Using Cornstarch 5D Parallelism
Info
Cornstarch repository provides an end-to-end example
in examples/distributed/run_vlm_hybrid.py.
Using FSDP/DDP only may not be scalable depending on the infrastructure (e.g. slow inter-node networking). Cornstarch provides 5D parallelism (data parallelism, tensor parallelism, pipeline parallelism, context parallelism, and modality parallelism).
Creating MultimodalParallelPlugin
Cornstarch allows per-modality parallelization specification using modular information in MultimodalModel.
Recall that a MultimodalModel is organized with multiple ModalEncoderModules, one per modality encoder:
Cornstarch provides the same architecture to specify parallelization per modality encoder and llm:
Note
All encoders defined when creating MultimodalModel should have its corresponding plugin, otherwise an exception will be raised during parallelization.
Note
Parallelization is done lazily; the model is not parallelized until colossalai.booster.Booster.boost() is called.
Note
Currently using MultimodalParallelPlugin forces to use pipeline parallelism, as encoders and the LLM should be pipelined in different stages.
The structure of MultimodalParallelPlugin exactly follows that of MultimodalModel.
Each encoder and the language model must have their own ModalParallelPlugin, which specifies how each modality should be parallelized.
Specifying Parallelization
Each ModalParallelPlugin has four arguments for parallel configurations: tp_size, sp_size, sequence_parallelism_mode, and pipeline_template.
The arguments are mapped to the following three parallel dimensions:
- Tensor Parallelism (TP):
tp_size - Context Parallelism (CP):
sp_size,sequence_parallelism_mode, andcontext_parallel_distribution_mode. - Pipeline Parallelism (PP):
pipeline_template
Note
Cornstarch uses the term sequence_parallelism for backward compatibility: which is used by colossalai.
Cornstarch does not support Megatron's sequence parallelism that is used as a combination of tensor parallelism.
Tensor Parallelism
All embedding and linear layers are partitioned to tensor parallel ranks.
For attention layers, it is partitioned in head dimension; the number of heads of a model should be divisible to tp_size.
Note
Currently specifying different number of tp_size to different encoders or LLM is not supported.
Context Parallelism
Cornstarch supports Ulysses all-to-all style context parallelism and Llama context parallelism (head-by-head parallelism).
You can set sequence_parallelism_mode to all_to_all (Ulysses) or ring_attn (llama CP) to choose the context parallelism mechanism.
Encoders and the LLM can have different number of sp_size.
Note
If sp_size <= 1, sequence_parallelism_mode is ignored.
Note
Currently context parallelism is supported only for the LLM.
Context parallelism split sequeneces into subsets of tokens and distribute them into multiple ranks. There are multiple ways of partitioning sequences and distributing tokens into ranks that Corntarch supports:
uniform: The simplest way of such partitioning. Chunk every sequence intocp_world_sizechunks, and each rank takes one portion.zigzag: For causal attention, the amount of computation becomes imbalanced if tokens are uniformly distributed.zigzagpartitions the sequence into2 * cp_world_sizeand each rank gets one portion from the upper half and another from the lower half, the workload sum of which is always balanced in causal attention.makespan_min: In multimodal LLM, attention should no longer be simple causal; vision tokens should attend each other regardless of their location (previous vision tokens can attend to the future vision tokens). In this form of attention, zigzag is no longer be balanced,makespan_mincomputes the amount of workloads per token block (128 tokens per block) and distributes them to minimize overall makespan (execution time). The number of tokens per rank may be different depending on the amount of workloads.
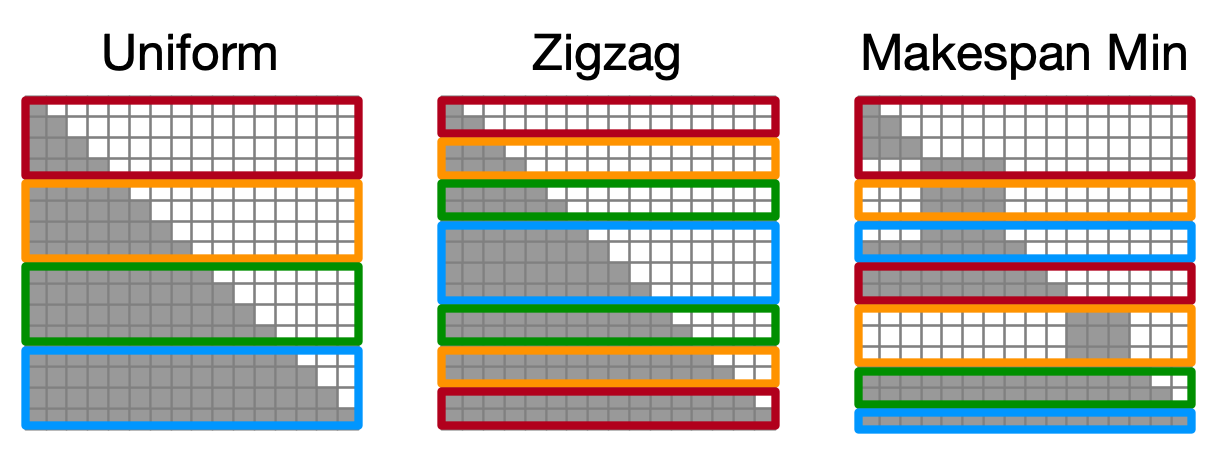
The token distribution scheme can be configured by passing cornstarch.shardformer.shard.shard_config.ContextParallelDistributionMode.[UNIFORM | ZIGZAG | MAKESPAN_MIN] to LLM's shard_config.context_parallel_distribution_mode. Default is MAKESPAN_MIN.
Pipeline Parallelism
Cornstarch uses pipeline template to specify pipeline parallelism (adopted from Oobleck), instead of simply having the number of pipeline stages, to let users to specify pipeline stages more freely.
A way of creating a pipeline template is as follows.
- Get all layers required to be included in a template.
- Split the layers into a list of sublayers properly, each of which will be a set of layers of a pipeline stage.
- Create a
cornstarch.pipeline_template.PipelineTemplateinstance.
For HF models, Cornstarch provides a way of automatically getting all layers in a model:
Split the list of layers to however you want as list[list[str]].
For example, If you want to make a 2-stage pipeline template,
which will assign the embed_tokens layer and first 16 decoder layers to the first pipeline stage, all the others to the second pipeline stage.
Now create a pipeline template:
which will give you a 2-stage pipeline template for LlamaForCausalLM:
Note
Cornstarch verifies if the pipeline template is for the given unimodal model by checking its name and modules_per_stage. It will raise an exception if a pipeline template for different model is given.
Warning
Currently Cornstarch pipeline parallelism does not support synchronizing tied word embeddings.
Data Parallelism
Data Parallelism is not explictly specified by some arguments. Instead, Cornstarch automatically infers how many data parallel replicas are needed by computing the number of ranks in a parallel multimodal LLM and divide the world size by it.
Note
Cornstarch does not optimize rank assignment and leaves it to user responsibility. The example above assigns 3 GPUs to the encoders and 8 GPUs to the LLM; if each node has 8 GPUs, cross-node GPUs may be assigned to the LLM (5 GPUs from one node, and 3 GPUs from another one).
Modality Parallelism
Cornstarch executes multiple modality encoders in parallel, as there is no dependency between them.
By using cornstarch.plugin.multimodal_parallel_plugin.MultimodalParallelPlugin, modality encoders will be assigned to different devices and executed separately.
If you do not want to parallelize them, consider using cornstarch.plugin.encoders_colocated_plugin.EncodersColocatedPlugin, which colocates multiple modality encoders into the same GPUs and execute them sequentially.
Running Parallelized Module
Pipeline parallelism interleaves forward passes and backward passes; therefore existing code for training (loss = model(**inputs); loss.backward()) is not compatible.
You have to use Booster.execute_pipeline() API to run the model:
Refer to Colossal-AI Booster API and examples for more details about the arguments.